
谷歌AI破译古籍再创新高峰:错误率仅0.56%,准确
作者:365bet体育 发布时间:2025-11-16 10:14
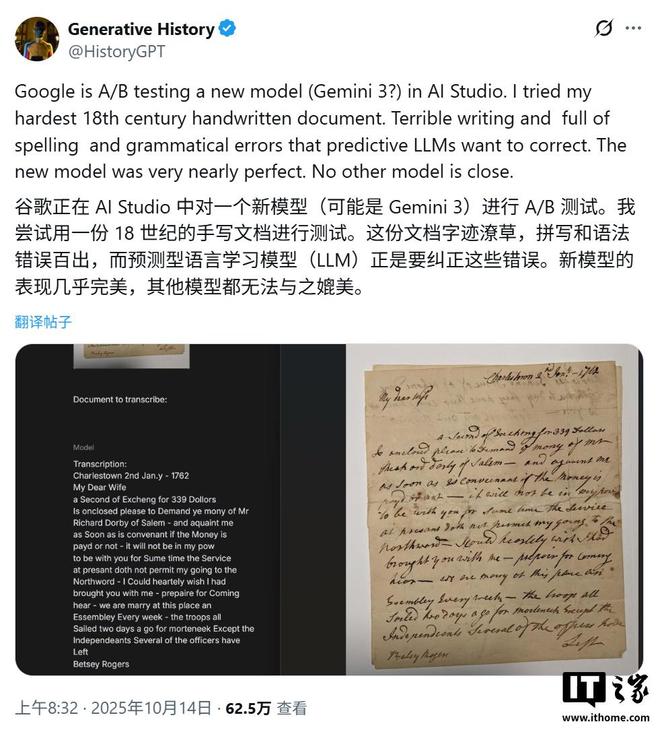 IT之家 11 月 16 日报道 科技媒体 Golem 昨日(11 月 15 日)发表博文,报道谷歌通过其 AI studio 平台,正在测试一种尚未命名的 AI 模型,该模型接近人类专家破译难以破译的历史手稿的水平。它援引一篇博客文章称,历史学家马克·汉弗莱斯(Mark Humphries)使用专门开发的基准数据集来系统地测试模型的性能。结果显示,在处理5份较难的历史手稿时,该模型的整体字符错误率约为1.7%,大多数错误涉及标点符号和大小写,而不是单词本身。 Humphries 的分析进一步指出,在不计入歧义标点符号和大写错误的情况下,AI 模型的字符错误率降低至 0.56% 左右,相当于每转录 200 个字符就有 1 个错误。奥尔巴尼分类帐的页面抄录自新的版本,其准确性令人惊讶。发现的未知双子座模型的性能与抄写历史文献的专业人类工作者相当。测试的文档涵盖了18至19世纪的各种笔迹风格,包括笔迹难以辨认、拼写错误和语法不一致的复杂样本,进一步凸显了该模型的强大功能。该模型最令人惊讶的表现是它超越了简单的文本转录,并展示了复杂的推理能力。在编写18号商人的日记时,原文中包含了一份糖购买记录,仅标有数字“145”,没有计量单位。谷歌的人工智能模型没有直接翻译“145”,而是翻译“14磅,5盎司”。研究人员发现,AI通过逆向计算账本中记录的总价,并结合英国货币(英镑、先令、笔)之间的关系,成功推导出了这个结果。ce) 和时间重量单位。虽然初步结果令人鼓舞,但汉弗莱斯也强调了当前分析的局限性。由于该模型通过 A/B 测试偶尔出现,因此对其进行大规模系统测试存在困难,并且迄今为止仅分析了基准数据集中约 10% 的样本。
特别声明:以上内容(如有则包括图片、视频)由自媒体平台“网易号”用户上传发布。本平台仅提供信息存储服务。
注:以上内容(包括图片和视频,如有)由网易HAO用户上传发布,网易HAO为社交媒体平台,仅提供信息存储服务。
IT之家 11 月 16 日报道 科技媒体 Golem 昨日(11 月 15 日)发表博文,报道谷歌通过其 AI studio 平台,正在测试一种尚未命名的 AI 模型,该模型接近人类专家破译难以破译的历史手稿的水平。它援引一篇博客文章称,历史学家马克·汉弗莱斯(Mark Humphries)使用专门开发的基准数据集来系统地测试模型的性能。结果显示,在处理5份较难的历史手稿时,该模型的整体字符错误率约为1.7%,大多数错误涉及标点符号和大小写,而不是单词本身。 Humphries 的分析进一步指出,在不计入歧义标点符号和大写错误的情况下,AI 模型的字符错误率降低至 0.56% 左右,相当于每转录 200 个字符就有 1 个错误。奥尔巴尼分类帐的页面抄录自新的版本,其准确性令人惊讶。发现的未知双子座模型的性能与抄写历史文献的专业人类工作者相当。测试的文档涵盖了18至19世纪的各种笔迹风格,包括笔迹难以辨认、拼写错误和语法不一致的复杂样本,进一步凸显了该模型的强大功能。该模型最令人惊讶的表现是它超越了简单的文本转录,并展示了复杂的推理能力。在编写18号商人的日记时,原文中包含了一份糖购买记录,仅标有数字“145”,没有计量单位。谷歌的人工智能模型没有直接翻译“145”,而是翻译“14磅,5盎司”。研究人员发现,AI通过逆向计算账本中记录的总价,并结合英国货币(英镑、先令、笔)之间的关系,成功推导出了这个结果。ce) 和时间重量单位。虽然初步结果令人鼓舞,但汉弗莱斯也强调了当前分析的局限性。由于该模型通过 A/B 测试偶尔出现,因此对其进行大规模系统测试存在困难,并且迄今为止仅分析了基准数据集中约 10% 的样本。
特别声明:以上内容(如有则包括图片、视频)由自媒体平台“网易号”用户上传发布。本平台仅提供信息存储服务。
注:以上内容(包括图片和视频,如有)由网易HAO用户上传发布,网易HAO为社交媒体平台,仅提供信息存储服务。 下一篇:没有了